PageSpeed Insights Adds an Agentic Browsing Audit
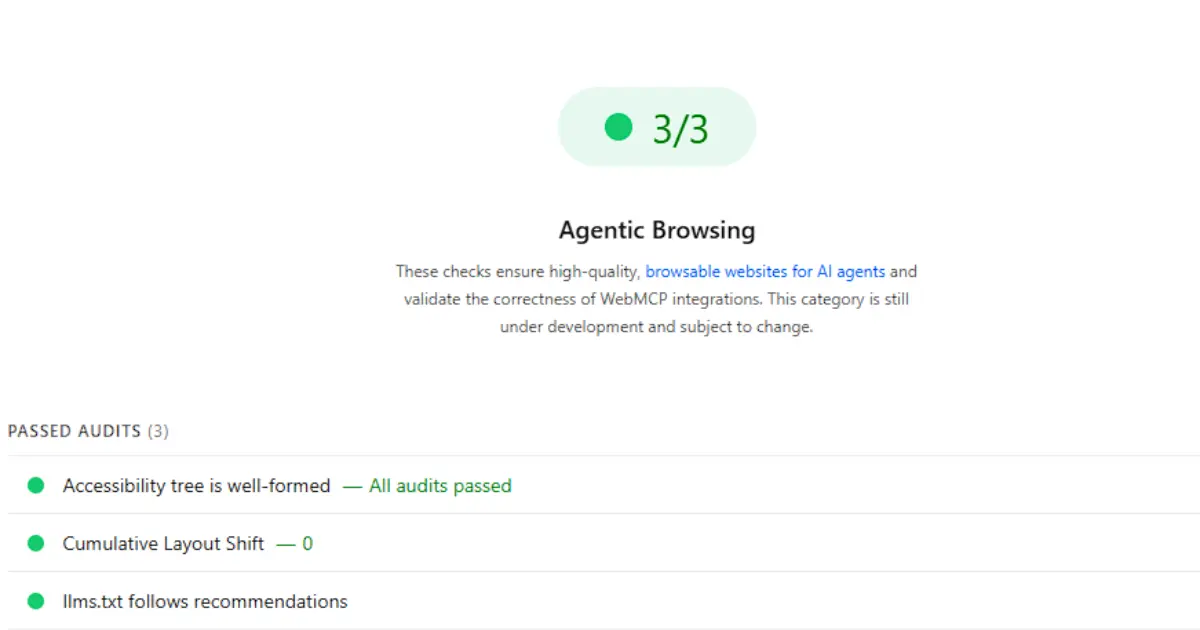
PageSpeed Insights now reports an Agentic Browsing category: a set of Lighthouse audits that score how ready a page is for an AI agent to read, navigate, and act on without a human driving. Chrome shipped the category in Lighthouse 13.3.0 on 7 May 2026 and moved it out of experimental into the default config, so it appears automatically in Lighthouse on Chrome 150 or later, and in PageSpeed Insights within roughly two weeks of each Lighthouse release. It appears alongside the familiar Performance, Accessibility, Best Practices, and SEO categories, but unlike them it does not grade the page for human visitors: it is the first mainstream tool to score a page for the machines that read it.
What the category checks
The audits fall into three groups:
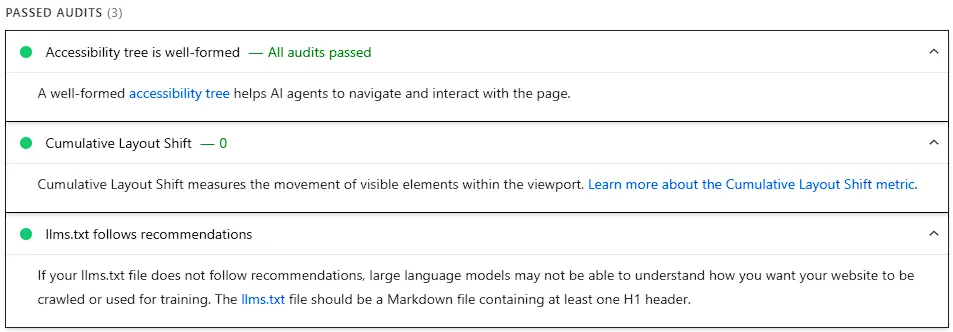
- Agent-centric accessibility. Whether the accessibility tree is well-formed: names and labels on interactive elements, correct roles and parent-child relationships, and visibility of interactive content. A clean accessibility tree is what lets an agent understand and operate a page’s controls.
- Stability and discoverability. Cumulative Layout Shift, because a shifting layout is as disruptive to an agent locating an element as to a human, plus an
llms.txtcheck. The latter is titled “llms.txt follows recommendations”: it does not just test for the file’s presence but checks that, if present, it is a valid Markdown file with at least one H1 header. A missing file is treated as not applicable rather than a failure. - WebMCP integration. Three checks tied to WebMCP: form coverage (forms that could carry WebMCP annotations), tools registered (the tools exposed via
navigator.modelContext), and schema validity (whether those tool schemas parse correctly).
The category does not produce a weighted score out of 100. It reports a ratio of passed checks, because the standards for the agentic web are still emerging and Chrome’s stated intent is to surface actionable signals rather than a ranking. The denominator counts only the audits that apply to the page, not all six: a site with no llms.txt and no WebMCP is scored out of two (accessibility tree and CLS), so you might see 0/2, 2/2, or 3/3 depending on what applies and passes. On a page with no WebMCP implementation, the three WebMCP audits show as “not applicable” or unscored rather than failing.
The WebMCP audits need an origin trial
The accessibility and CLS checks run on any page. The llms.txt audit only scores when the file exists: a site with no llms.txt sees it move to “not applicable (unscored)” alongside the WebMCP audits, rather than failing. The three WebMCP audits are more constrained still: they only run at all on Chrome 150 or later with the WebMCP origin trial registered, and Chrome weights them low while the standard stabilises. WebMCP itself entered a public origin trial in Chrome 149 in early June 2026 and is not called by any major AI agent in production yet, so the WebMCP audits are a build-time correctness check for sites already prototyping the standard, not a prompt to adopt it.

This is a diagnostic, not a ranking signal
The most important caveat: Agentic Browsing is a Chrome developer diagnostic. Passing it does not affect Google Search indexing, rankings, or AI citation rates. Lighthouse audits page-level engineering quality; it does not feed Google’s ranking systems.
That distinction matters most for the llms.txt check. Google Search has repeatedly stated that its systems do not use llms.txt, and Ahrefs data from May 2026 found 97% of published llms.txt files received no requests at all. Lighthouse auditing for the file does not contradict that: the audit is about agent navigation readiness when a browser-based agent acts on a user’s behalf, a different question from search ranking or citation inclusion. A passing llms.txt audit is not evidence that publishing the file improves AI search visibility.
What this means
For most informational and editorial sites, the actionable parts of this report are the ones you should be doing anyway: a well-formed accessibility tree and low CLS are good for human users and assistive technology, not just agents. Treat those audits as a useful prompt to fix accessibility and layout-stability issues.
The WebMCP audits are only relevant to e-commerce, travel, booking, and SaaS sites already prototyping agent-callable tools. For everyone else they will sit as “not applicable”, which is the correct outcome, not a problem to fix.
The broader signal is that agent readiness now has a measurable surface inside Google’s own tooling. Google is not alone in this, and was not first: Cloudflare launched its isitagentready.com scanner in April 2026, a few weeks before the Lighthouse category shipped. Cloudflare’s tool grades sites across a much wider agent stack, including discoverability, content accessibility, bot access control, and capabilities such as API catalogs, MCP servers, and commerce protocols. The two are complementary rather than competing, Google’s audit is page-level and runs inside an existing developer tool, while Cloudflare’s scans the whole domain. Both point the same way: agent readiness is becoming something tools measure. For the wider picture of what agents need to discover, read, and act on a site, see agent-readiness. That makes it easier to reason about concretely, but these scorecards measure engineering correctness, not search or AI-citation performance. Do not let a 3/3 be mistaken for a ranking win.
Sources
- Lighthouse agentic browsing scoring — Chrome for Developers
- llms.txt audit — Chrome for Developers / Lighthouse
- WebMCP — Chrome for Developers
- 97% of llms.txt files got no requests, Ahrefs data shows — Search Engine Journal
- Is your site ready for AI agents? — Cloudflare blog
- Is It Agent Ready? — Cloudflare
More news
-
Bing Webmaster Tools Adds AI Visibility Insights: Intents, Topics, Citation Share and Compare
Bing Webmaster Tools has added four AI visibility features, letting publishers see why their content is cited in Copilot answers, not just which queries triggered it.
-
Microsoft launches Web IQ: Bing-powered grounding API for AI agents
Microsoft's Web IQ connects AI agents to Bing's index via passage-level grounding APIs. It already powers Copilot and ChatGPT's web responses.
-
Google Analytics Adds AI Assistant as Default Channel Group for Traffic Attribution
Google Analytics 4 now automatically classifies traffic from AI tools like ChatGPT, Claude, and Gemini as its own channel, replacing manual tracking workarounds.